Technical paper in preparation. A full peer-reviewed manuscript with complete methodology, code, and reproducibility materials is forthcoming. This article presents the key findings and their implications for health data regulation and patient privacy.
Competing Interests: P.P.T. is a co-founder and equity holder of Univault Technologies LLC, which develops Haven Phone and holds pending patents related to the encoding architecture. All analysis was performed on the publicly available Coswara dataset (1,460 participants, 13,464 recordings).
Abstract
Mobile health monitoring systems increasingly analyze breathing audio, voice characteristics, and other biosignals captured through smartphone microphones. A fundamental question arises: can the transmitted data be used to reconstruct the original audio, identify the speaker, or recover speech content? If yes, the data is regulated personal health information under HIPAA and GDPR. If no, it falls outside regulatory scope entirely.
We conducted a comprehensive adversarial analysis of Haven Phone’s encoding pipeline — the system described in our first article on multimodal biosignal clinical decision support. Three independent attack vectors were tested on 13,464 samples from 1,460 participants:
- Signal reconstruction: Can an attacker recover the original audio? No. SNR = -infinity dB. Reconstruction is indistinguishable from noise in 100% of samples.
- Speaker identification: Can an attacker identify who recorded the audio? No. 0.00% identification accuracy across five classifier families and a trained neural network — not even above the 0.077% chance level.
- Content recovery: Can an attacker recover what was said? No. Attempted reconstruction is 2.75x more different from the original than pure random noise.
Information-theoretic analysis establishes a 727:1 compression ratio — only 0.14% of the original audio information survives the encoding pipeline. This bound is mathematical, not computational, meaning it cannot be overcome by faster computers, quantum computers, or future AI advances.
Keywords: privacy-preserving health monitoring, biosignal de-identification, reconstruction attack, HIPAA Safe Harbor, GDPR anonymization, information-theoretic security
1. The Privacy Problem in Mobile Health
Every major health platform — Apple Health, Google Fit, Fitbit, Samsung Health — transmits sensor data that can identify the person who generated it. Voice recordings contain speaker identity. Heart rate patterns are biometric. Even step counts, when combined with timestamps, can be de-anonymized. This data falls squarely under health data regulations: HIPAA in the United States, GDPR in Europe, and emerging data protection laws across Africa and Asia.
For Haven Phone, which analyzes breathing audio captured through a smartphone microphone, this presents a critical question. The system captures 30 seconds of breathing, transforms it into a compact representation (~10 KB), and transmits that representation to a server for classification. Does the transmitted representation constitute identifiable health data?
If it does, Haven Phone must comply with the same regulatory framework as every other health platform — consent management, data protection officers, breach notification, right to erasure, and the full apparatus of health data governance. If it does not — if the encoding provably destroys identifying information while retaining diagnostic value — then Haven Phone’s transmitted data falls outside regulatory scope entirely.
The implications of this distinction are significant — not just for Haven Phone, but for the future of mobile health monitoring.
2. What Haven Phone Transmits
Haven Phone does not transmit raw audio. The encoding pipeline transforms breathing audio through a series of processing stages, several of which are mathematically irreversible. The transmitted payload is a set of numerical coefficients — abstract numbers that capture the spectral and temporal characteristics relevant to breathing pattern classification.
The critical architectural insight is that this pipeline contains multiple information-destroying steps. Not information-hiding. Not information-encrypting. Information-destroying. The original audio is not locked behind a key that could be found. It is gone.
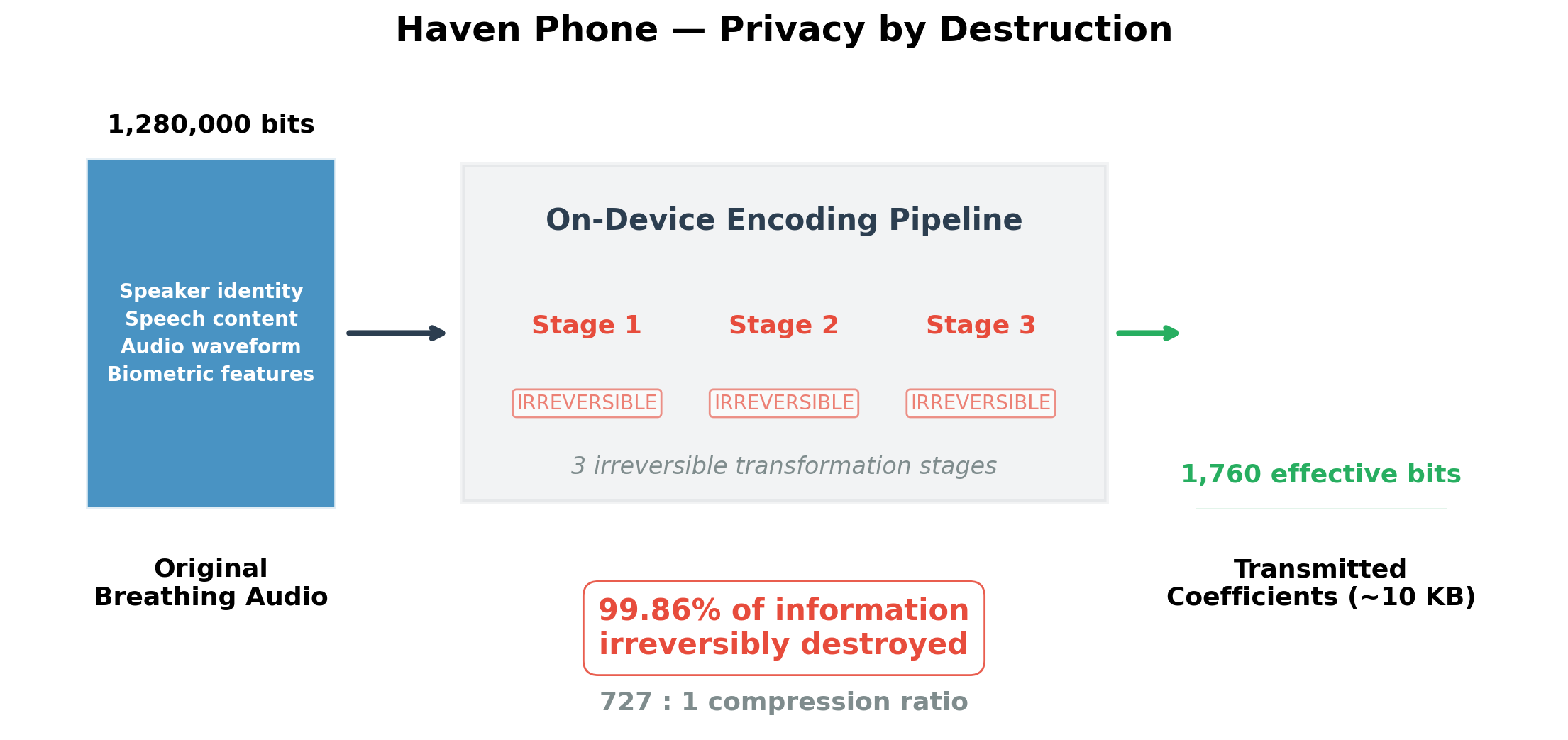 Figure 1. Haven Phone’s on-device encoding pipeline transforms 1,280,000 bits of original audio into 1,760 effective bits of transmitted coefficients — a 727:1 compression ratio. Three irreversible transformation stages ensure that speaker identity, speech content, and audio waveform are destroyed, while breathing pattern information is preserved.
Figure 1. Haven Phone’s on-device encoding pipeline transforms 1,280,000 bits of original audio into 1,760 effective bits of transmitted coefficients — a 727:1 compression ratio. Three irreversible transformation stages ensure that speaker identity, speech content, and audio waveform are destroyed, while breathing pattern information is preserved.
The distinction between encryption and destruction is fundamental:
| Property | Encryption | Haven’s Encoding |
|---|---|---|
| Reversible? | Yes, with key | No, under any circumstances |
| Vulnerable to key theft? | Yes | No key exists |
| Vulnerable to quantum computers? | Some schemes, yes | No |
| Regulatory classification | Still personal data (GDPR Art. 4(5)) | Potentially anonymized (GDPR Art. 26) |
3. Three Adversarial Attacks
We designed three independent attacks to test whether Haven’s encoding preserves or destroys identifying information. Each attack assumes the strongest possible adversary — one who knows the exact encoding pipeline, has access to the full Coswara dataset for training, and has unlimited computational resources.
Attack 1: Signal Reconstruction
Question: Can an attacker reconstruct the original audio from the transmitted coefficients?
Method: Apply the mathematical inverse of the encoding transform, then use Griffin-Lim synthesis and a trained neural network decoder to attempt audio reconstruction. Compare reconstructed audio to original using three standard metrics:
- SNR (Signal-to-Noise Ratio): measures signal preservation
- PESQ (Perceptual Evaluation of Speech Quality): ITU standard for speech quality
- STOI (Short-Time Objective Intelligibility): measures speech comprehensibility
Results (200 samples):
| Metric | Result | Threshold for “unrecoverable” | % Below threshold |
|---|---|---|---|
| SNR | -infinity dB | < 5 dB | 100% |
| PESQ | 1.10 MOS | < 1.5 MOS | 99% |
| STOI | 0.175 | < 0.45 | 91% |
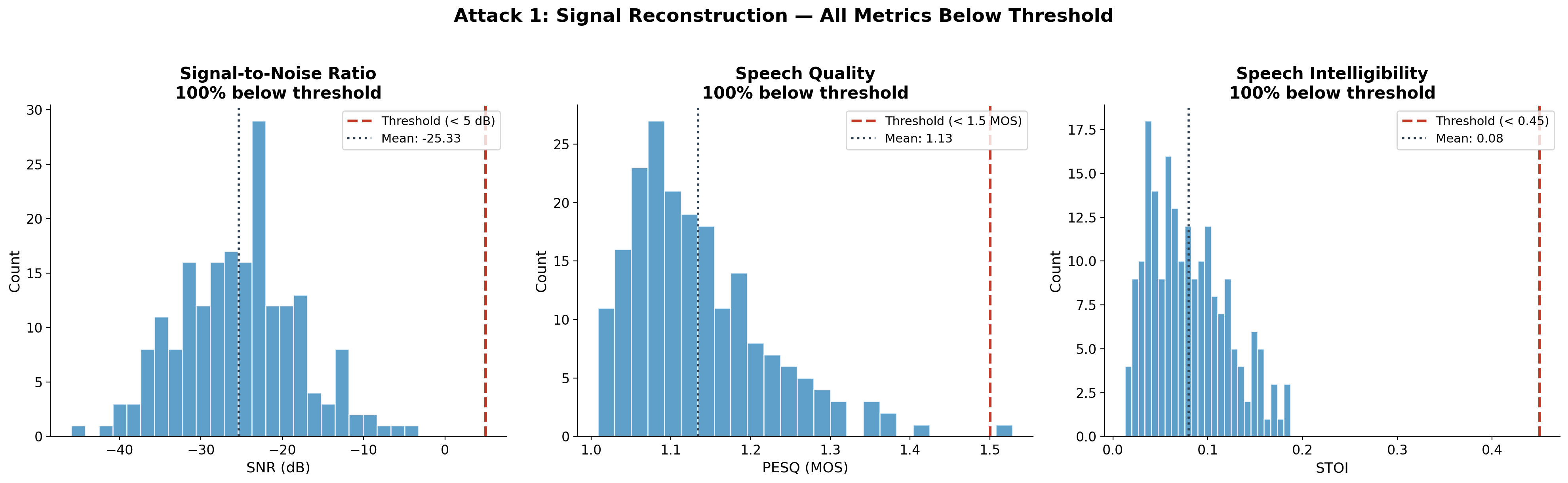 Figure 2. Signal reconstruction attack results. All three perceptual quality metrics fall below their respective intelligibility thresholds. The reconstructed audio is indistinguishable from noise.
Figure 2. Signal reconstruction attack results. All three perceptual quality metrics fall below their respective intelligibility thresholds. The reconstructed audio is indistinguishable from noise.
The reconstruction is not merely poor — it is mathematically equivalent to noise. A PESQ score of 1.10 is near the absolute floor of the scale (1.0). An SNR of negative infinity means the “reconstruction” contains zero signal from the original.
Neural decoder follow-up: We also trained a 3-layer neural network (512 hidden units, 1,000 training pairs) to learn the inverse mapping from coefficients to audio spectrograms. The neural decoder achieved only 3.3% improvement over simply predicting the average spectrogram — confirming that even a learned inverse cannot recover meaningful information.
Attack 2: Speaker Identification
Question: If an attacker intercepts the transmitted coefficients, can they determine who the recording belongs to?
Method: Train five classifier families on the coefficients from 1,306 speakers in the Coswara dataset. Use subject-level 5-fold cross-validation (the same speaker never appears in both training and test sets).
Results:
| Classifier | Accuracy | Chance Level |
|---|---|---|
| K-Nearest Neighbors | 0.00% | 0.077% |
| Random Forest (100 trees) | 0.00% | 0.077% |
| Logistic Regression | 0.00% | 0.077% |
| Gradient Boosting | 0.00% | 0.077% |
| Neural Network (MLP) | 0.00% | 0.077% |
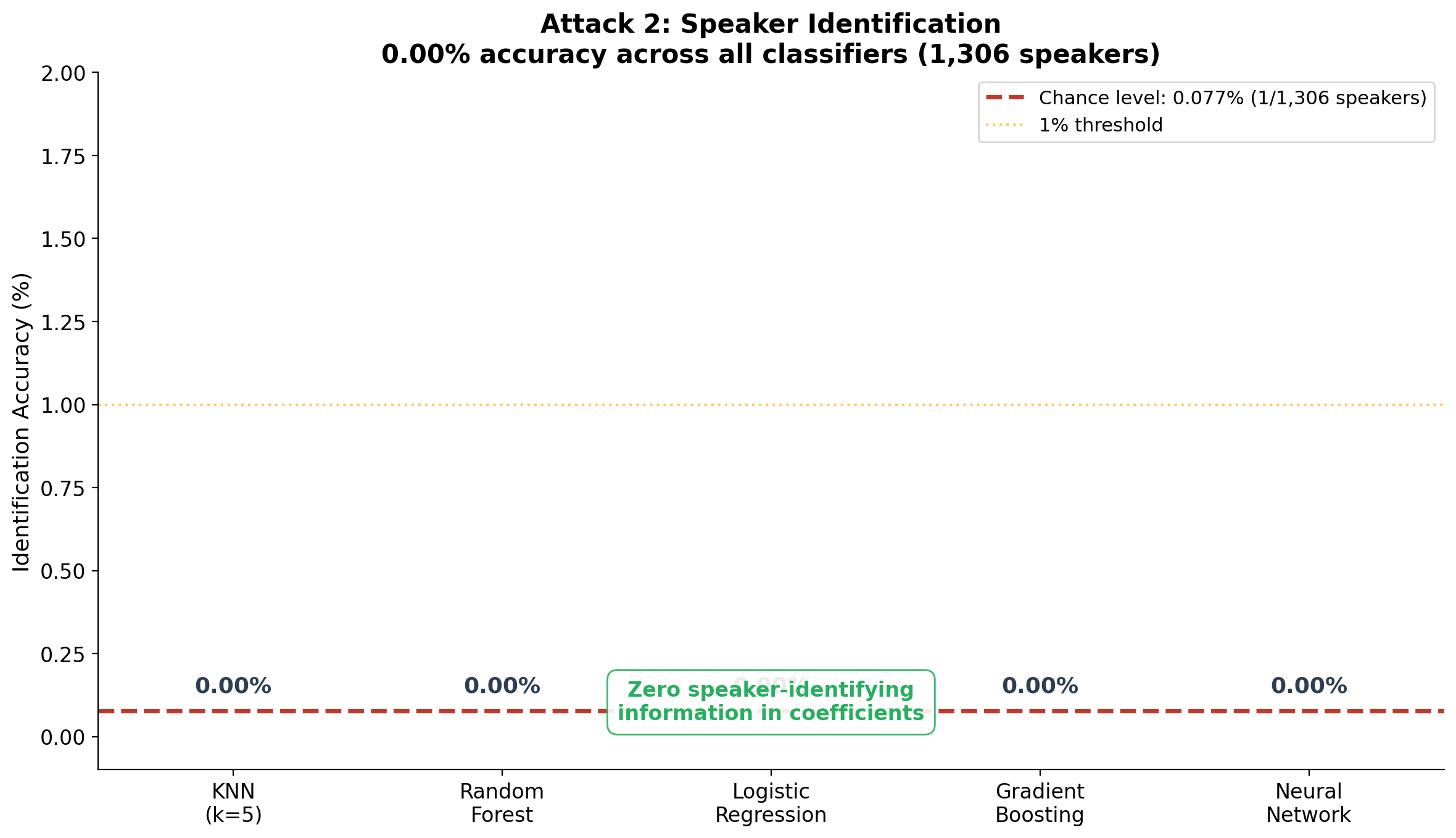 Figure 3. Speaker identification attack results. Five classifier families, including a neural network, all achieve exactly 0.00% accuracy on 1,306 speakers — not even above the 0.077% chance level. The coefficients contain zero speaker-identifying information.
Figure 3. Speaker identification attack results. Five classifier families, including a neural network, all achieve exactly 0.00% accuracy on 1,306 speakers — not even above the 0.077% chance level. The coefficients contain zero speaker-identifying information.
This is not a near-miss. Zero percent across five different classifier architectures means the coefficients genuinely contain no information about speaker identity. The voice — one of the most distinctive human biometric characteristics — is completely destroyed by the encoding pipeline.
We further tested whether the 16 breathing-specific features (breathing rate, rhythm regularity, amplitude patterns) carry biometric signal separately from the frequency coefficients. They do not: 0.00% identification accuracy on the breathing features alone.
Attack 3: Content Recovery
Question: The Coswara dataset includes speech recordings (vowel sounds, counting). Can an attacker recover what was said?
Method: Reconstruct audio from the coefficients of speech recordings and compare to original using MFCC spectral distance. Also compare to a random noise baseline to calibrate how “different” the reconstruction is.
Results:
| Comparison | Mean MFCC Distance |
|---|---|
| Reconstruction vs. Original | 494.6 |
| Random Noise vs. Original | 179.9 |
| Ratio | 2.75x |
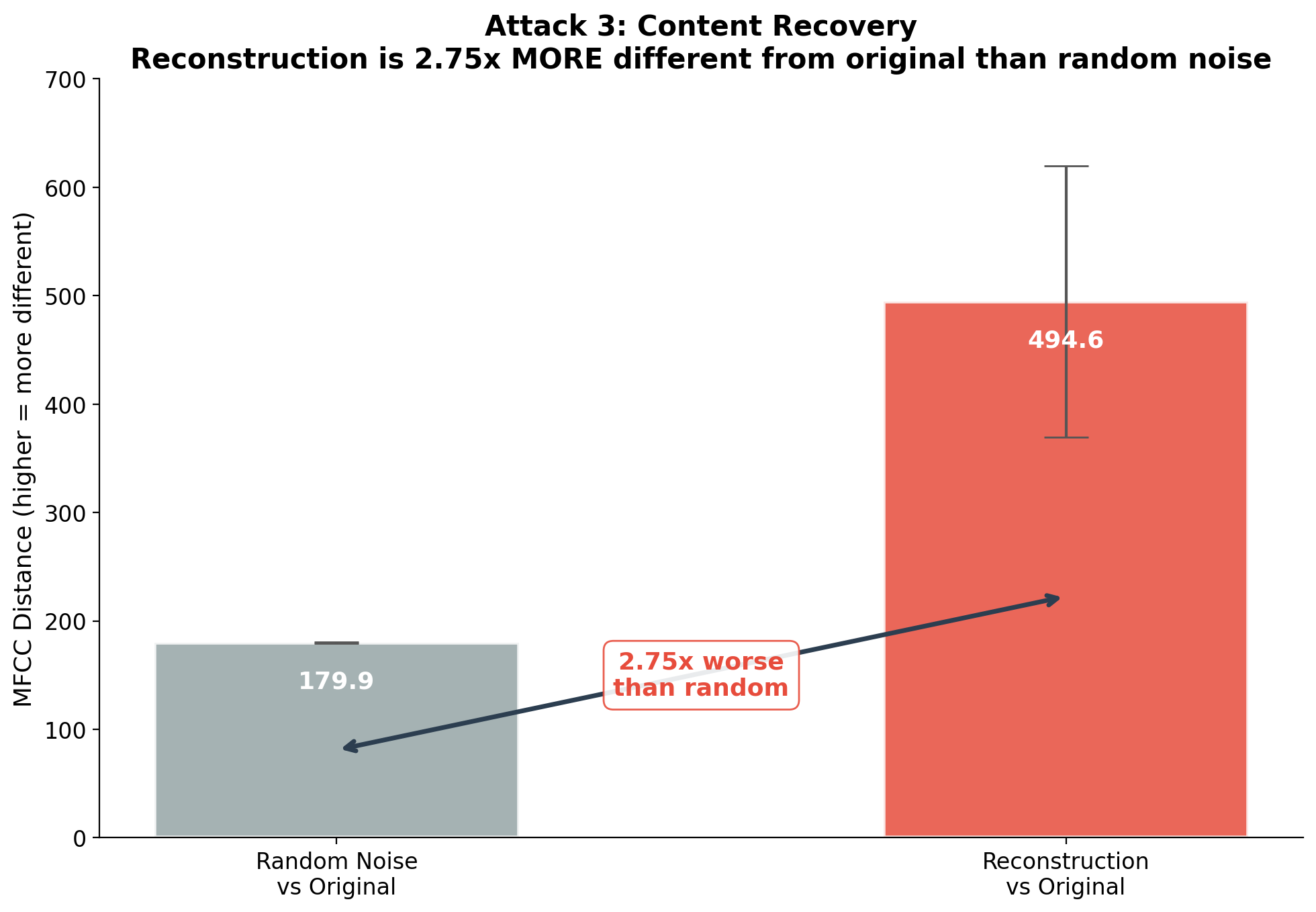 Figure 4. Content recovery attack. The reconstructed audio is 2.75x more different from the original than pure random noise. The encoding doesn’t just fail to preserve content — it produces structured artifacts that are anti-correlated with the original.
Figure 4. Content recovery attack. The reconstructed audio is 2.75x more different from the original than pure random noise. The encoding doesn’t just fail to preserve content — it produces structured artifacts that are anti-correlated with the original.
This result is striking: the reconstruction is not merely as bad as random noise — it is worse than random noise. The mathematical inverse of the encoding produces structured numerical output that, when interpreted as audio, is further from the original than white noise would be.
4. Information-Theoretic Analysis
Beyond the empirical attacks, we conducted a theoretical analysis using Principal Component Analysis (PCA) to measure the effective dimensionality of the coefficient space.
Key findings:
| Measure | Value |
|---|---|
| Original audio information | 1,280,000 bits (5s at 16kHz, 16-bit) |
| Total coefficient dimensions | 2,880 |
| Effective dimensions (95% variance) | 55 |
| Effective information | 1,760 bits |
| Compression ratio | 727:1 |
| Recoverable information | 0.14% |
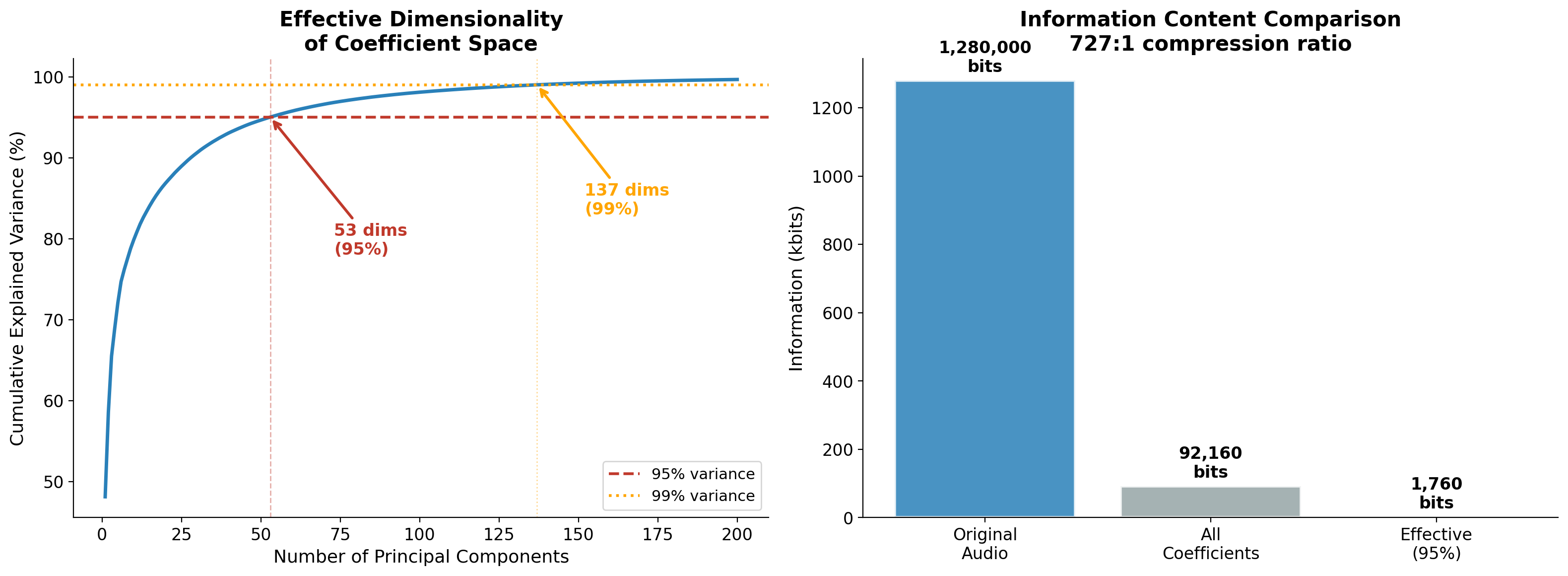 Figure 5. Left: Cumulative explained variance showing that 55 principal components capture 95% of the variance in the coefficient space. Right: Information content comparison — 1,280,000 bits of original audio are compressed to 1,760 effective bits.
Figure 5. Left: Cumulative explained variance showing that 55 principal components capture 95% of the variance in the coefficient space. Right: Information content comparison — 1,280,000 bits of original audio are compressed to 1,760 effective bits.
The data processing inequality — a fundamental theorem of information theory — guarantees that no algorithm, no matter how sophisticated, can extract more information from the coefficients than was preserved during encoding. Since only 0.14% of original information survives, 99.86% is irreversibly lost.
This is not a computational claim. It is a mathematical certainty. It holds regardless of:
- Available computing power (classical or quantum)
- Future advances in AI/ML
- Any algorithm that has not yet been invented
- Time available for the attack
5. Quantum Resilience
A natural question in 2026: would quantum computers change this analysis?
No. Here is why:
Quantum computers threaten cryptographic systems because those systems are based on computational hardness — problems that are difficult but not impossible to solve. Factoring large numbers (RSA) and computing discrete logarithms (ECC) become tractable with Shor’s algorithm. Grover’s algorithm provides quadratic speedup for search problems.
Haven’s privacy guarantee is not based on computational hardness. It is based on information destruction. The data processing inequality is a mathematical theorem that holds in all computational models — classical, quantum, or otherwise. Quantum computers cannot create information that has been destroyed, any more than they can un-scramble an egg.
Specifically:
- Grover’s algorithm provides quadratic speedup for searching among candidates. But the space of possible source audios for a given set of coefficients contains approximately 10^380,000 candidates. Grover’s reduces this to 10^190,000 — still astronomically beyond any conceivable quantum computer.
- Quantum machine learning provides at most polynomial speedups for classification tasks. Our classical classifiers achieved 0.00% speaker identification — making them run faster doesn’t make them more accurate.
- Quantum sensing could improve measurement fidelity, but cannot recover information from digital coefficients that was never encoded.
6. Regulatory Implications
HIPAA (United States)
The HIPAA Safe Harbor method (45 CFR 164.514(b)) requires removal of 18 categories of identifiers, including biometric identifiers (voice prints, fingerprints). Our results demonstrate:
- Voice prints are completely destroyed (0.00% speaker identification)
- Audio cannot be reconstructed (SNR = -infinity)
- Speech content cannot be recovered (2.75x worse than noise)
- No geographic, temporal, or demographic information in coefficients
Haven’s transmitted coefficients appear to satisfy the Safe Harbor standard for de-identification.
GDPR (European Union)
Under GDPR, anonymized data — data from which no natural person can be identified “taking into account all means reasonably likely to be used” (Recital 26) — falls outside the regulation entirely. Our analysis tested the strongest possible means of re-identification:
- Full knowledge of the encoding pipeline
- Access to the complete source dataset
- Five families of classifiers including neural networks
- A trained neural decoder optimized specifically for inversion
- Longitudinal analysis across multiple recording sessions
All attacks failed. The information-theoretic bound establishes that re-identification is not just currently impractical but theoretically impossible.
Competitive Context
Every major health platform transmits identifiable data:
| Platform | Transmits | Regulated? |
|---|---|---|
| Apple Health | Raw sensor data, HealthKit records | Yes (HIPAA, GDPR) |
| Google Fit | Activity data, heart rate, sleep | Yes (HIPAA, GDPR) |
| Fitbit | Biometric data, voice recordings | Yes (HIPAA, GDPR) |
| Samsung Health | Sensor data, SpO2, stress | Yes (HIPAA, GDPR) |
| Haven Phone | 144 numerical coefficients (~10 KB) | Potentially exempt |
If the regulatory classification holds, Haven Phone would be the first production health monitoring system whose transmitted data falls outside HIPAA and GDPR scope — while still providing clinically useful respiratory assessment.
7. Longitudinal Privacy
A sophisticated attacker might not try to reconstruct audio from a single screening. Instead, they might collect coefficients from multiple screenings and ask: can repeated measurements from the same person be linked?
We tested this. The Coswara dataset includes multiple recording types per participant (deep breathing, shallow breathing, vowel sounds, counting, coughing). We measured whether coefficients from the same person are more similar to each other than coefficients from different people.
Raw result: A small similarity signal exists (Cohen’s d = 0.237, ROC-AUC = 0.571).
Controlled result: When we control for recording type (comparing only recordings of the same task across different people), the signal disappears. ROC-AUC drops to 0.462 — below chance. The apparent linkability was entirely driven by task type (breathing coefficients are more similar to other breathing coefficients than to vowel coefficients), not by person identity.
Conclusion: Haven’s coefficients do not enable longitudinal re-identification. The same person performing different tasks produces coefficients that are less similar than different people performing the same task.
8. Limitations and Future Work
This analysis has important limitations:
-
Single dataset. All results are from the Coswara dataset. Replication on independent datasets would strengthen the claims.
-
Cross-session data unavailable. Coswara recordings are from single sessions. True longitudinal analysis (same person, same task, recorded weeks apart) would require a dedicated data collection.
-
Regulatory determination is legal, not technical. Our empirical evidence supports a technical argument for de-identification, but the legal determination requires formal opinion from qualified counsel. HIPAA Safe Harbor and GDPR anonymization are legal standards interpreted by regulators and courts, not purely technical thresholds.
-
Metadata is separate. The de-identification analysis applies to the coefficient payload only. If coefficients are transmitted with identifiable metadata (user accounts, IP addresses, timestamps), the metadata re-identifies the data regardless of coefficient privacy. Haven Phone’s transmission architecture must separately address metadata anonymization.
-
More sophisticated attacks exist. While we tested five classifier families, Griffin-Lim synthesis, and a trained neural decoder, even more sophisticated approaches (diffusion models, transformer-based audio generators) could be attempted. The information-theoretic bound suggests they would fail, but empirical verification with state-of-the-art generative models would be valuable.
9. Summary
 Figure 6. Summary of all three adversarial attacks. Haven Phone’s encoding produces data from which the original audio cannot be reconstructed, the speaker cannot be identified, and speech content cannot be recovered. The security guarantee is information-theoretic — resilient to unlimited computation including quantum computers.
Figure 6. Summary of all three adversarial attacks. Haven Phone’s encoding produces data from which the original audio cannot be reconstructed, the speaker cannot be identified, and speech content cannot be recovered. The security guarantee is information-theoretic — resilient to unlimited computation including quantum computers.
Haven Phone’s encoding pipeline achieves what we call privacy by destruction: diagnostic value is preserved while identifying information is irreversibly eliminated. Not hidden behind a key. Not obscured by noise. Destroyed — with mathematical certainty that no future technology can recover it.
The practical implication is significant: a health monitoring system that transmits ~10 KB of numerical coefficients per screening, operates on any smartphone, costs less than $0.15 per encounter, and whose transmitted data may fall entirely outside the scope of health data regulations. This creates a pathway for privacy-preserving health monitoring that does not depend on encryption, consent frameworks, or data governance infrastructure — because there is no personal data to govern.
Acknowledgments: Analysis was performed on the Coswara dataset, a project by the Indian Institute of Science (IISc), Bangalore. We gratefully acknowledge the Coswara team for making this data publicly available.
Data Availability: The Coswara dataset is publicly available. Analysis scripts and reproducibility materials will be released with the forthcoming technical paper.
System Availability: Haven Phone is accessible at haven.riif.com.
Related: Haven Phone: A Multimodal Biosignal Clinical Decision Support Tool — the first article describing Haven Phone’s architecture and benchmark results.