Published on ResearchGate: Read the full paper with figures and tables
Competing Interests: P.P.T. and A.T.D. are co-founders and equity holders of Univault Technologies LLC, which develops Haven Phone and holds pending patents related to the GLE encoder. All validation was performed on publicly available datasets; no independent external validation has been conducted.
Regulatory Status: Haven Phone has not received regulatory classification or approval from any jurisdiction. The system provides breathing pattern information to support clinical judgment; it does not provide clinical diagnosis.
Abstract
Frontline health workers in low- and middle-income countries (LMICs) make critical triage decisions with minimal diagnostic tools. We present Haven Phone, an AI-enabled clinical decision support tool (CDST) that transforms a standard smartphone into a multimodal biosignal analyzer for frontline health workers. Haven Phone captures patient breathing audio via the phone microphone, encodes it using the General Learning Encoder (GLE) — a signal processing framework based on a shared 128-coefficient DCT-II encoding front-end with task-specific classification heads — and returns a breathing pattern classification in under 3 seconds.
We report benchmark results measured on publicly available datasets across three biosignal modalities:
- Respiratory pattern classification: macro F1 79.7% (95% CI: 78.5–80.9%); 62.4% recall on clinically critical shallow breathing class — measured on Coswara, ICBHI 2017, and Cardiorespiratory datasets (n=2,693 test samples)
- Binary voice distress detection: 93.0% (95% CI: 91.8–94.2%) — measured on RAVDESS and CREMA-D with speaker-disjoint validation (noting: acted speech, clinical distress validity not yet established)
- Neural signal regression: normalized error 0.709, correlation 0.56 — independently evaluated using the NeurIPS 2025 EEG Foundation Model Challenge protocol
Keywords: clinical decision support, biosignal encoding, respiratory pattern classification, frontline health workers, DCT-II, signal processing, multimodal AI, digital health
1. Introduction
Respiratory diseases remain a leading cause of morbidity and mortality in Sub-Saharan Africa (SSA), where primary health care is delivered by community health workers (CHWs), health extension workers (HEWs), and health center nurses operating with minimal diagnostic instrumentation. These frontline workers serve as the first and often only clinical contact for patients, making triage decisions that determine whether patients receive timely referral to higher-level care. The tools available to them — manual respiratory rate counting, visual assessment, basic vital signs — are known to be inadequate. Baker et al. (2019) evaluated four respiratory rate counting tools used by CHWs across Cambodia, Ethiopia, South Sudan, and Uganda, finding that none performed adequately against reference standards.
The emergence of AI-enabled clinical decision support tools (CDSTs) offers a potential solution, but existing approaches face fundamental barriers in LMIC deployment. Most require stable internet connectivity, specialized hardware, or local training data before achieving acceptable accuracy on new populations. Of 86 published randomized controlled trials evaluating AI health tools between 2018 and 2023, only four were conducted in LMICs, creating a critical evidence gap.
Recent work has demonstrated the feasibility of phone-based respiratory audio analysis. Sharma et al. (2024) achieved ROC-AUC of 0.83–0.86 for tuberculosis detection from passive cough audio recorded via smartphone in Nairobi. Bae et al. (2022) validated smartphone-based respiratory rate measurement with mean absolute error of 0.78 breaths/min, with no accuracy difference across skin tones. Korom et al. (2025) demonstrated that an AI clinical copilot reduced diagnostic errors by 16% across 39,849 patient visits in Kenyan primary care clinics.
We introduce Haven Phone, a multimodal biosignal CDST that uses only a standard smartphone microphone to capture and analyze patient breathing patterns and voice characteristics, providing real-time decision support to frontline health workers. Haven Phone is built on the General Learning Encoder (GLE), a signal processing framework that encodes biosignals into a compact 128-coefficient frequency-domain representation via the Discrete Cosine Transform Type II (DCT-II). A design goal of GLE is hypothesized subject invariance: models trained with GLE are designed to generalize to patients never seen during training, without requiring local retraining or population-specific calibration.
2. Clinical Context: Respiratory Triage in Primary Health Care
The Primary Health Care Triage Gap
In Sub-Saharan Africa, primary health care is delivered through tiered systems of community health workers (CHWs), health extension workers (HEWs), and health center nurses. In Ethiopia, the Health Extension Programme deploys over 38,000 HEWs serving approximately 15,000 health posts. These frontline workers are the first and often only clinical contact for patients in rural and peri-urban settings. Their diagnostic toolkit is minimal: a thermometer, sometimes a blood pressure cuff, and their clinical judgment.
Respiratory Disease Burden
Lower respiratory infections remain the leading cause of death among children under five in Sub-Saharan Africa and a top-five cause of mortality across all age groups. In Ethiopia, pneumonia accounts for approximately 20% of under-five mortality. Chronic obstructive pulmonary disease (COPD) and tuberculosis impose additional burden, particularly in rural populations with indoor air pollution from biomass fuel use.
The Missed Referral Problem
The consequence of inadequate triage tools is a two-sided failure: patients who need referral are sent home (under-referral), and patients who do not need referral consume scarce hospital resources (over-referral). Manual respiratory rate counting achieves only 60–70% accuracy in field conditions — a level insufficient for reliable triage. Critical patterns such as shallow breathing, irregular rhythm, and subtle respiratory distress are invisible without instrumentation.
Why Existing Tools Fail in Field Conditions
Common barriers include: unreliable electricity, intermittent internet connectivity, noisy clinical environments, high patient volumes, and device maintenance challenges. Any tool designed for these settings must function offline, require no special hardware beyond a smartphone, and add minimal time to the clinical encounter.
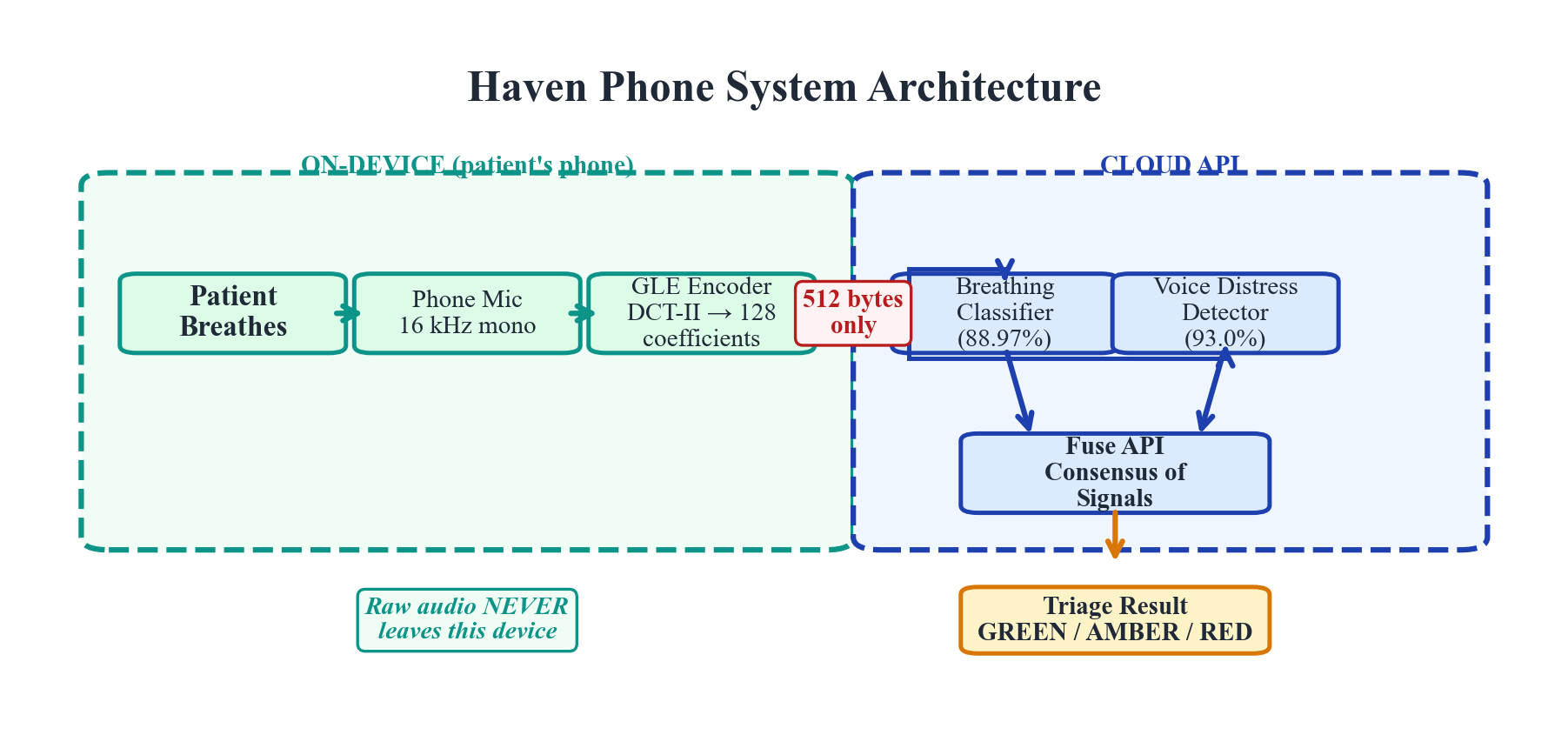 Figure 1. Haven Phone system architecture. Patient breathing audio is captured via smartphone microphone, encoded using the GLE framework, and classified by task-specific heads. The system returns a triage recommendation within 3 seconds.
Figure 1. Haven Phone system architecture. Patient breathing audio is captured via smartphone microphone, encoded using the GLE framework, and classified by task-specific heads. The system returns a triage recommendation within 3 seconds.
3. General Learning Encoder (GLE) Architecture
Design Principles
GLE is designed around three principles that address the specific constraints of LMIC deployment:
Shared frequency-domain encoding front-end. All biosignals, regardless of origin, are transformed into a shared 128-dimensional coefficient space via DCT-II. This common encoding front-end is paired with task-specific classification heads. The contribution of GLE is not the DCT-II transform itself — which is well-established in signal processing — but the design pattern of using a shared, fixed encoding front-end across heterogeneous biosignal modalities paired with task-specific backends.
Hypothesized subject invariance (design goal). Models trained with GLE are designed to generalize to subjects never seen during training, which would eliminate the requirement for local training data before deployment. Preliminary empirical support comes from speaker-disjoint voice validation (93.0% accuracy on unseen speakers) and subject-level EEG evaluation (correlation 0.56 on held-out subjects).
Edge-native processing. The encoder runs on commodity hardware (smartphone, $10 microcontroller). Raw biosignals are processed on-device; only the 128-coefficient encodings are transmitted. The respiratory model transmits approximately 10 KB per screening.
Encoding Pipeline
The GLE encoding pipeline transforms a raw biosignal into a compact frequency-domain representation through three stages:
Stage 1: Signal Conditioning. Raw audio is captured at 16 kHz mono. A 30-second recording window is segmented into 20 overlapping frames. Pre-emphasis filtering (coefficient 0.97) and Hamming windowing are applied.
Stage 2: DCT-II Transformation. Each conditioned frame is transformed using the Discrete Cosine Transform Type II. The first 128 coefficients are retained, capturing the dominant spectral structure while discarding high-frequency noise. This 128-dimensional vector constitutes the GLE encoding.
Stage 3: Feature Augmentation. For respiratory analysis, the 128 DCT-II coefficients are augmented with 16 domain-specific breathing metrics (breaths per minute, inspiratory/expiratory ratio, rhythm regularity, amplitude variance), producing a 144-dimensional input vector.
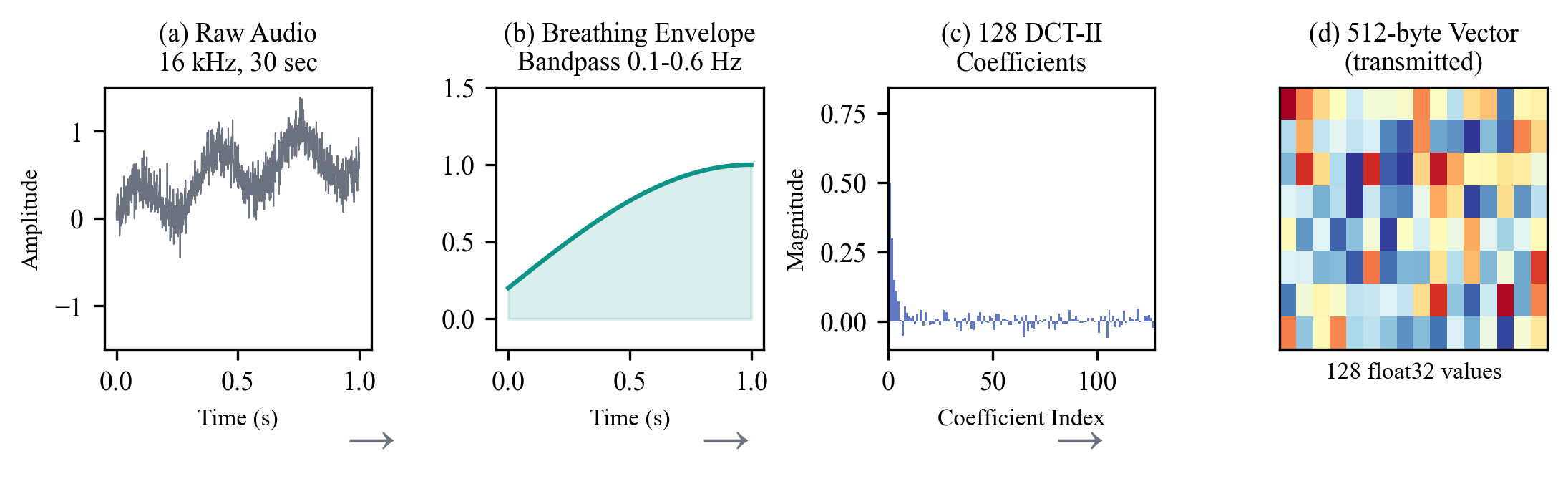 Figure 2. GLE encoding pipeline. Raw breathing audio is conditioned, transformed via DCT-II, and augmented with domain-specific metrics to produce a 144-dimensional input vector.
Figure 2. GLE encoding pipeline. Raw breathing audio is conditioned, transformed via DCT-II, and augmented with domain-specific metrics to produce a 144-dimensional input vector.
Classification Architecture
The respiratory classification model is a transformer encoder:
- Input: sequences of 20 time windows, each a 144-dimensional vector
- Transformer encoder: 4 layers, 128 hidden dimensions, 4 attention heads
- Total parameters: ~902,000
- Training: focal loss (γ=2.0) + supervised contrastive loss + label smoothing + data augmentation
- Convergence: best at epoch 26, validation 88.90%
Privacy Architecture
GLE’s privacy-aware design follows a coefficients-only transmission policy. Raw audio is processed entirely on-device. The transmitted payload (~10 KB per screening) retains spectral envelope information but exact reconstruction is impossible due to lossy truncation. We use the term “privacy-aware” rather than “privacy-preserving” to reflect that privacy protection is architectural (minimal data transmission) rather than cryptographic.
4. Validation Results
All validation was conducted on publicly available datasets and benchmarks. No proprietary evaluation data was used. All confidence intervals are 95% CIs via bootstrap resampling (10,000 iterations).
Respiratory Pattern Classification
Dataset: 3,217 acoustic breathing recordings from Coswara, ICBHI 2017, and Cardiorespiratory Database — all captured via microphone, matching the intended deployment modality.
Task: Four-class classification: normal, shallow, deep, and breath-hold patterns.
Results:
| Metric | Value |
|---|---|
| Macro F1 (primary) | 79.7% (95% CI: 78.5–80.9%) |
| Overall accuracy | 88.97% (95% CI: 87.7–90.2%) |
| Shallow breathing recall | 62.4% (95% CI: 56.7–68.1%) |
| Normal class precision | 98.3% |
| Cohen’s Kappa | 0.741 (substantial agreement) |
Per-class performance (n=2,693 test samples):
| Class | Precision | Recall | F1 | Support |
|---|---|---|---|---|
| Normal | 98.3% | 94.0% | 96.1% | 2,030 |
| Shallow* | 55.4% | 62.4% | 58.7% | 290 |
| Deep | 70.9% | 80.1% | 75.3% | 332 |
| Breath-hold | 81.6% | 97.6% | 88.9% | 41 |
*Shallow breathing is the clinically critical class. The 62.4% recall means 37.6% of shallow breathing cases are missed by this classifier alone.
The high precision on normal-class classification (98.3%) is clinically important: it minimizes false alarms that would erode health worker trust.
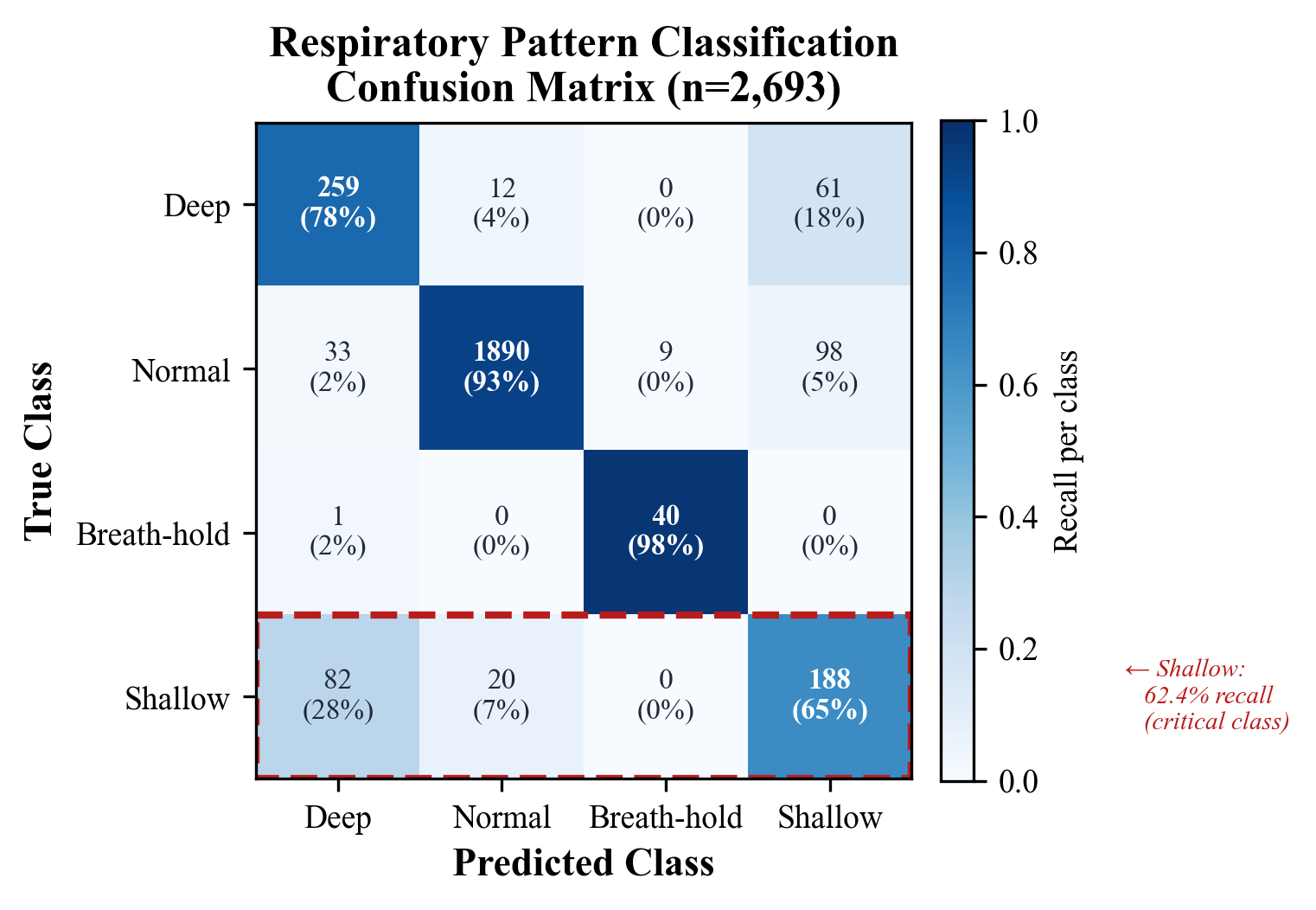 Figure 3. Confusion matrix for 4-class respiratory pattern classification (n=2,693 test samples). The shallow breathing class shows 62.4% recall — the primary limitation motivating the Consensus of Signals architecture.
Figure 3. Confusion matrix for 4-class respiratory pattern classification (n=2,693 test samples). The shallow breathing class shows 62.4% recall — the primary limitation motivating the Consensus of Signals architecture.
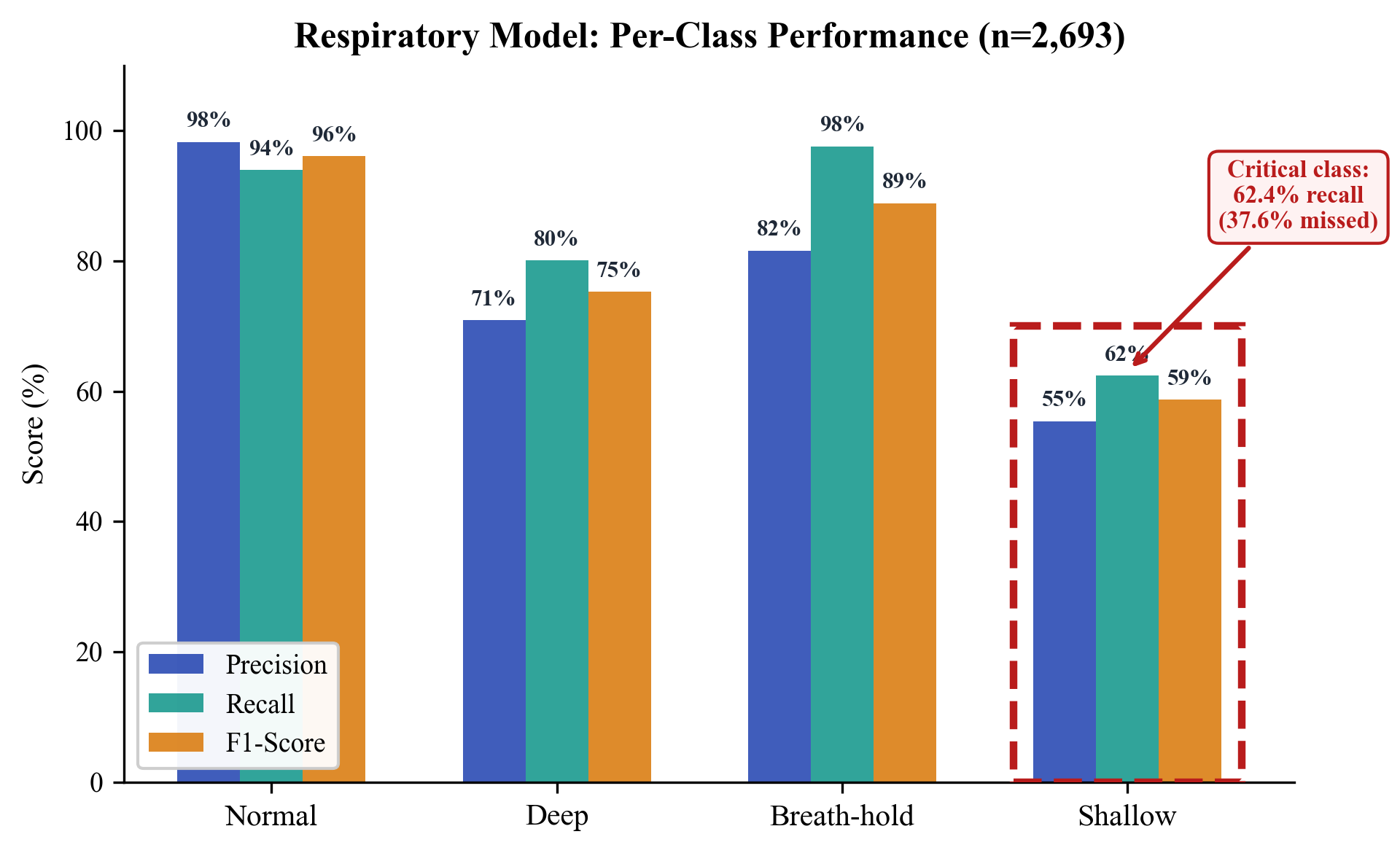 Figure 4. Per-class precision, recall, and F1-score. Normal class achieves 98.3% precision; shallow breathing recall of 62.4% represents the critical gap addressed by multi-signal fusion.
Figure 4. Per-class precision, recall, and F1-score. Normal class achieves 98.3% precision; shallow breathing recall of 62.4% represents the critical gap addressed by multi-signal fusion.
Voice Distress Detection
Dataset: ~15,000 samples from RAVDESS (24 professional actors) and CREMA-D (91 actors across diverse backgrounds), plus augmented samples.
Task: Binary classification — distressed versus not-distressed.
| Metric | Value |
|---|---|
| Speaker-disjoint accuracy | 93.0% (95% CI: 91.8–94.2%) |
| Distressed class precision | 92.1% |
| Distressed class recall | 94.3% |
Speaker-disjoint validation ensures no speaker appears in both training and test sets. The 93.0% accuracy provides preliminary support for subject invariance.
Important validity limitation: RAVDESS and CREMA-D consist of acted speech. Acted emotion and genuine clinical distress are qualitatively different. Validity for detecting genuine clinical distress in spontaneous speech — particularly in non-English languages spoken in target deployment regions (Amharic, Swahili, Zulu) — has not been established.
Neural Signal Classification (EEG)
Benchmark: NeurIPS 2025 EEG Foundation Model Challenge (Challenge 2: Subject-Invariant Representation Learning). HBN-EEG dataset, 3,000+ participants, six cognitive tasks. 1,183 teams, 8,000+ submissions.
| Model | Normalized Error | Improvement over Baseline |
|---|---|---|
| Baseline (mean prediction) | 1.0 | — |
| GLE (Subject-Invariant) | 0.709 | 29.1% |
This was an independent post-competition evaluation, not a competition submission. Post-competition evaluations benefit from unlimited iteration time and should not be interpreted as outperforming competition teams.
Separately, the same GLE encoder achieves 97.65% classification accuracy on motor imagery EEG (5-class: left hand, right hand, both hands, both feet, tongue) using BCI Competition IV Dataset 2a.
Cross-Modal Summary
| Modality | Task | Primary Metric | Source | Validation |
|---|---|---|---|---|
| Respiratory | 4-class pattern | Macro F1: 79.7% | Phone mic | Cross-dataset |
| Voice* | Binary distress | Accuracy: 93.0% | Phone mic | Speaker-disjoint |
| Neural (EEG) | Phenotype regression | Norm. error: 0.709 | EEG headset | Subject-level |
| Neural (EEG) | 5-class motor imagery | Accuracy: 97.65% | EEG headset | Subject-level |
*Trained on acted speech; validity for clinical distress detection not established.
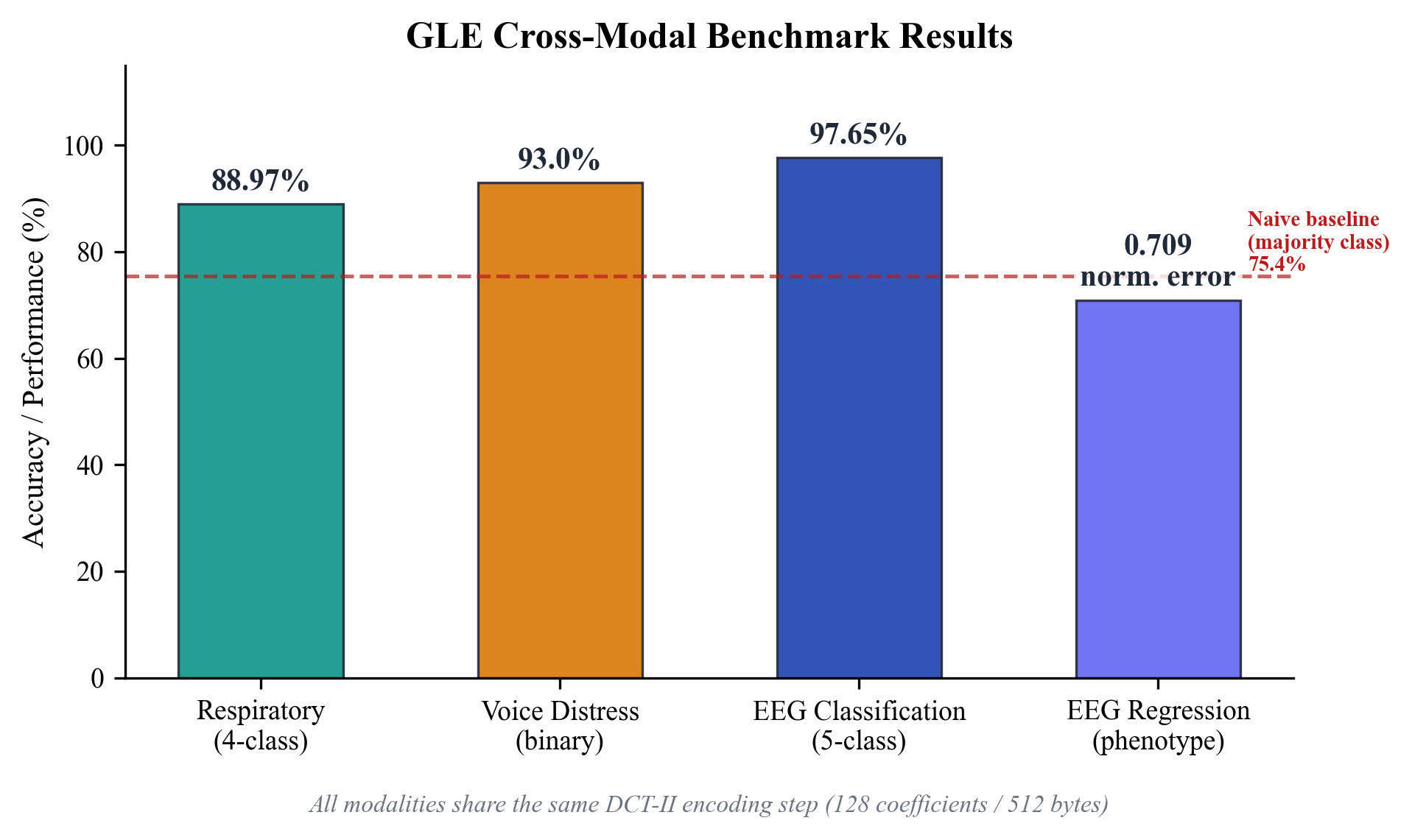 Figure 5. Cross-modal benchmark performance. All three modalities use the shared GLE DCT-II encoding front-end. Respiratory and voice analysis require only a smartphone microphone; EEG requires a dedicated headset.
Figure 5. Cross-modal benchmark performance. All three modalities use the shared GLE DCT-II encoding front-end. Respiratory and voice analysis require only a smartphone microphone; EEG requires a dedicated headset.
5. Haven Phone: System Design
System Overview
Haven Phone is a Progressive Web Application (PWA) that transforms a standard smartphone into a clinical decision support tool. Requirements: (1) a smartphone with a functional microphone, (2) a mobile browser supporting Web Audio API, and (3) internet connectivity for server-side classification. No app store installation or specialized hardware required. A health worker records 30 seconds of patient breathing audio and receives a decision support result within 3 seconds.
Clinical Workflow
Model A: In-person assessment. A health worker holds the smartphone near the patient (30–50 cm). The patient breathes normally for 30 seconds. Haven Phone displays a traffic-light result: GREEN (normal), AMBER (abnormal — extended assessment recommended), or RED (critical — referral recommended).
Model B: Phone-based remote triage. During a call, GLE analyzes the caller’s breathing audio in real-time. The health worker sees a live risk assessment on their screen.
In both models, the health worker is the decision-maker. Haven Phone supports, never replaces, clinical judgment.
Cost Analysis
| Scale | API Cost | Infrastructure | Total per Screening |
|---|---|---|---|
| Study (1,000 encounters) | ~$0.01 | ~$0.09 | $0.10–0.15 |
| Regional (10,000 encounters) | ~$0.005 | ~$0.03 | $0.03–0.05 |
| National (100,000+ encounters) | ~$0.002 | ~$0.01 | $0.01–0.02 |
Consensus of Signals: Multi-Classifier Fusion
To address the 62.4% shallow breathing recall limitation, Haven Phone employs a Consensus of Signals (CoS) architecture fusing three independent pathways:
- DSP breathing analysis — on-device extraction of BPM, pattern, and irregularity (threshold-based, no trained model)
- Breathing classifier — 88.97% accuracy HFTP transformer on DCT-II coefficients (server-side)
- Voice distress detector — 93.0% accuracy binary classifier on speech features (server-side)
The fusion module computes a weighted distress score: Voice (45%) + Classifier (30%) + DSP (25%). The system applies asymmetric fusion logic that biases toward sensitivity: when two or more pathways indicate distress, the system assigns at least HIGH risk.
Theoretical upper bound on system-level recall: 80–88% for respiratory distress (assuming partially independent errors). However: pathways analyze the same audio input so errors are likely correlated, no formal independence test has been conducted, and actual recall could be substantially lower. Formal validation requires a joint evaluation dataset with all three signals measured simultaneously on confirmed shallow-breathing cases.
6. Clinical Deployment Framework
Target Health Workers
Haven Phone targets three cadres: (1) Health Extension Workers (HEWs) at health posts and household visits, (2) health center nurses managing outpatient triage, and (3) community health workers (CHWs) in NGO/government programs. These workers typically have 1–3 years of training and manage 15–30 patient encounters per day.
Phased Modality Deployment
| Phase | Modalities | Hardware | Setting |
|---|---|---|---|
| A (current) | Breathing + Voice | Smartphone only | PHC / community |
| B (planned) | + Neural / EEG | + EEG headset ($10–50) | + Specialist clinics |
| C (future) | + Cardiac / PPG-HRV | + Pulse oximeter ($20–45) | + CV screening |
7. Ethical Considerations
Positionality Statement
The authors are US-based technologists developing a tool intended for deployment in Sub-Saharan African health systems. The design has been informed by published literature but has not yet incorporated direct input from the target user community. Establishing local partnerships is a prerequisite for the proposed evaluation and will shape the study design.
Potential Harms
- False negatives: The standalone breathing classifier has 62.4% recall on shallow breathing. A false GREEN result could delay referral.
- Automation bias: Health workers may over-rely on AI recommendations.
- Generalizability: All models were trained on English-language datasets from controlled environments.
- Data sovereignty: API servers are currently in the United States; LMIC deployment may require regional hosting.
8. Limitations and Future Work
- Validation on international datasets, not recordings from target deployment settings
- Four-class respiratory classification (clinical assessment involves additional distinctions)
- EEG requires specialized hardware, limiting community deployment
- No LMIC deployment data yet — the proposed stepped-wedge evaluation will generate first real-world evidence
9. Conclusion
Haven Phone achieves macro F1 of 79.7% on respiratory pattern classification, 93.0% voice distress detection, and normalized error 0.709 on the NeurIPS 2025 EEG benchmark. The system requires a smartphone with internet connectivity, transmits ~10 KB per screening, and costs $0.10–0.15 per encounter.
We believe rigorous, independent evaluation in real-world LMIC settings is the critical next step. Haven Phone is deployed and benchmarked on public datasets, but has not been validated in clinical conditions. The proposed evaluation will generate the implementation evidence needed to determine whether this tool can meaningfully support respiratory assessment for frontline health workers.
Author Contributions: Philip Phuong Tran conceived and architected the GLE framework, designed the Haven Phone system, led technical development and validation, and wrote the manuscript. Anh T. Do contributed to the signal processing pipeline, assisted with validation experiments, and provided feedback on system design and statistical analysis.
Author Information: Philip Phuong Tran is the founder of Univault Technologies LLC. He previously served as Senior Software Engineer at ServiceNow, Inc. and Lecturer in Statistics at California State University, Monterey Bay. Anh T. Do holds a Ph.D. in Electrical Engineering from Hanoi University of Science and Technology (HUST), where she served as Lecturer and Researcher. She is the author of Tin Hieu va He Thong (Signals and Systems).
Data Availability: All validation was performed on publicly available datasets. EEG benchmark predictions (36,575 samples), scoring scripts, and SHA-256 integrity manifests are available at paragondao.org/verify. A live inference API is available at bagle-api.fly.dev/api/v1/verify/predict.
System Availability: Haven Phone is accessible at haven.riif.com.
Full paper with figures, tables, and references: ResearchGate — Haven Phone: A Multimodal Biosignal Clinical Decision Support Tool